
Understanding Sparklyr Deployment Modes | RStudio Webinar - 2017
This is a recording of an RStudio webinar. You can subscribe to receive invitations to future webinars at https://www.rstudio.com/resources/webinars/ . We try to host a couple each month with the goal of furthering the R community's understanding of R and RStudio's capabilities. We are always interested in receiving feedback, so please don't hesitate to comment or reach out with a personal message
image: thumbnail.jpg
Transcript#
This transcript was generated automatically and may contain errors.
Hello everyone, thank you for joining today. So we are continuing the series of webinars about Sparklyr. The first one I did was introducing Sparklyr, and I mentioned that I said some of the different aspects of deploying inside to talk about them today.
Javier did two in the middle, which felt a little bit out of sequence, and that's because he wasn't going to be able to make it today, so I took this one. So if it's really out of sequence, that's the reason why.
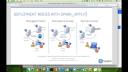
So I have in front of you here the different deployment modes. And this is essentially, if we were to take the deployment modes from the Apache website, the official Spark website here. So if I can go here, and I go deploying, you'll notice that it says standalone, mesos, and yarn. So you have these three. These match right here. You know, mesos, which is just a symbol for mesos and yarn, and then the standalone cluster. So these are the two sections right here that cover the ones that Spark is talking about.
And then we have the deployments based on the articles from our website, which talks about local and cluster, right? So this diagram here is meant to show basically the two together, right? How can we work with Spark VR and Spark in both of the deployment modes?
Managed cluster and standalone modes
So the first one is talking about a managed cluster, right? It's either managed through yarn, which is the most common, and then managed through mesos. Usually, whenever you have a managed cluster, that means that the resources are being managed centrally, and that you have a master node and then some slave nodes in the cluster. Whenever we talk about adding R and Spark VR to the cluster, it usually means that we're going to add it to one of the nodes, usually like an edge node, right? So you don't have to have R in every single package installed in every single node.
That's one of the big advantages I feel of Spark VR is because it's a very great approach, which I talked about in the first webinar. And simple approach allows it to not have to be running in every single node.
Same thing for standalone cluster. You'll notice that it's not a managed network, and that means that there's not a service that coordinates everything. What it is, is there's an actual machine that's called the master node that is the one that coordinates all the work. So usually, you can install the R and Spark VR in one of the other nodes, but also you can install in the master node, and I've done that both ways. I usually end up putting the master node myself, just because the master node doesn't give any resources once you open a new Spark connection.
This standalone cluster is actually really useful whenever you want to basically get your feet wet with an actual Spark implementation. If you want to try it out and you don't want to build an entire data lake, you can actually build something like this in the cloud. Like with AWS, you can set up a few boxes, a few what they call EC2 instances, which is the virtual servers, and connect them just like if they were physical. And we actually have instructions about that in our website as well.
If I go to spark.studio.com, and I have the link in the deck. So what I just want to show you on your deployment, Amazon EC2. The reason why I'm showing you this is because I recently updated it to kind of show you the instructions on how to do a more recent version of Spark. In this case, it would be Spark 2.1.0. So this set of instructions, again, if you want to start kind of trying it out, you would be able to do that with standalone.
Again, most common is YARN, just because usually you have a business that has a data lake. Standalone, I've seen several deployments in companies, and that's because they have existing grid computers that they want to start using with Spark. So they're able to kind of do that switch over, and then they're able to process the data. So one of the questions is, of course, where's the data coming from?
So in YARN, you have the data and the data lake inside the Hadoop cluster, but in standalone, it needs to be ingested somehow. We'll talk about that in a minute.
Remote cluster and Livy connectivity
Also, you notice this remote cluster, but it's really managed cluster. It would be another way of connecting. I actually considered putting this graph right here, because that would be more appropriate, in a sense, but it felt very cluttery, very hard to read. So just think remote cluster, managed cluster, both in YARN. And the idea here is that there's a lot of cases where you cannot install R and SparklyR in one of the edge nodes for whatever reason, you know, the separation of duties between IT and the data science team, or it's just that the clusters are locked down. You can't really do it. Then Libby would be a good option, and Javier talked about that in his previous webinar. So I just wanted to bring that out, that that is another way of connecting. I've heard of a few companies that are actually doing that.
Just keep in mind that our support for Libby is definitely much improved since version 5, but I think you will have to do a good review of how this service works, because you had to start a service, a Libby service inside the cluster, so your remote users can connect. And there's some considerations about security and also about data movement that you may want to consider, especially if you're an architect as well, that satisfies both the performance needs and security needs of your teams.
Local mode
And of course, local, which is like, as I mentioned in the Spark.studio.com site, we have local and remote, and cluster, excuse me. So local is really cool, and this is what I used in the first webinar, which is where you can actually start a Spark environment inside your laptop and be able to do all sorts of things just to try it out and be able to see how it works. If you recall, hopefully you were in that first one, I was able to switch over and see how the memory was being managed and show the UI and all that stuff. So it's really nice to do that.
Also, it works in other environments or operating systems that is not Linux. So all this would be in a Linux environment, except this. So local, the way that SparklyR was written, is that it can also run in Windows machines and in Mac. And I'm running on a Mac, and I did that demo. So this is a very good way of getting started.
Another thing that I noticed that you can do with SparklyR on a local mode, although it's not a prescribed thing to do, is if you want to use multiple cores for an analysis, that's something that you actually can do with your Spark environment. I actually found out that reading in data with a SparklyR connection on that file that is larger than one gigabyte is actually faster with SparklyR. So it was pretty nice to test out if you're curious about that. I definitely recommend trying to start in a local environment in your laptop.
Spark Apply and parallelization
All right, so recently we included, when I say we, I mean Javier included, Spark Apply function. This does change the paradigm a little bit, where we usually say, like I was saying here, you don't need to install R in every single node. In this case, you would if you want to do Spark Apply. So you don't have to have every library installed. That's something that the Spark Apply command will help you do. But you do need to have R in the nodes that you're running against.
So this is another consideration that I think needs to be said, that you don't have to have R in every single node if you're not going to use Spark Apply. But if you do, that changes the architecture a little bit. If you're a data scientist that is trying to find the easiest way to move your R code into and scale it up, this may be a good way, at least it looks at first. But just know that the code that you're running in here would have to be highly parallelized.
So a good way of thinking about this is, if I have a, let's say, a model that I want to run, or I want to fit against all the customers in my database, right? So I want to run a linear regression, a single linear regression against each individual customer. Then this model may work really well for you, because what it's doing is that it's going to take each of those customers, it's going to run the model in each worker node, and so it's going to separate the job that way. But let's say now, if I were to have a really large job, let's say I want to run the same model over all my customer activity, regardless of who the customer are, then there's not a good way of parallelizing it, and that's where that may not be the best choice to do the Spark Apply, or at least this way, it may be better to consider a native Spark machine learning library, or maybe an extension, like a H2O extension, for example. So I just want to mention that as you start using Spark Apply and getting acquainted with it, that that would be a good way of kind of knowing if you can switch or not.
Spark concepts: driver, master, worker, executor
Something that I found in speaking with some folks who are getting into Spark, or getting into R, we have an enterprise architect that's given us a call to understand all this stuff, and hopefully I see that there's other attendees. So if you're an R user that's getting into Spark, hopefully you'll see some of the stuff today, some new concepts. It takes me very early on in your Spark career, so I want to introduce some concepts. And if you're more on the architecture side, if you're in a big data environment already, hopefully some of the stuff I'll show you today will be also new to you, that you can see how it can be used for data analytics, at least from the R perspective.
So real quick, Spark concepts. So we have a driver, a master, a worker, and an executor. So just to clarify, sometimes the executor and the, when we say executor, it gets confused with a worker, or sometimes we hear the term of driver, and it's kind of hard to separate all of them because it's not the same terms that we use in group. So a driver is essentially the program that starts the Spark context. So that would be Spark VR in our case, right? And usually the machine or the server that starts that program is considered a driver node.
Then the master would be, you know, whomever is managing the Spark job, which is, it could be like I mentioned, either a machine itself, a server, or a service, right? Like Yarn. And then a worker is essentially the machines where you're going to actually do the heavy lifting, right? It's going to do the calculations. But where it gets tricky is the fact that each worker will not handle only one job. You can actually have multiple jobs running inside the same worker because how Spark works is that splits the work amongst executors. So you can technically have more than one executor inside a worker. And that is very important to know and to keep in mind because that goes back to how we do those deployments.
Data loading options
Another thing that is important to keep in mind is how we do data load with Spark VR. So at the end of the day, it boils down to two options that we have. The first option is to essentially tell Spark VR where the data is, right? So we tell Spark, hey, the data is in this high table. Go ahead and cache it, right? So when it caches it, it never goes through my R environment. It goes directly into the Spark cluster. And then I can use Spark VR to see the data in there. I can also tell, hey, my data is in this S3 bucket. Go get it. Then Spark can go and get it through a Spark package to be able to know how to read the S3 data and bring the data in. Again, it doesn't go through R.
So this is the best approach to have when we are using Spark to bring large data sets because what we found is that a lot of new users will try to do option two right off the bat, which is you can notice that the data is first. So in this case, you have a bunch of data that we load into our environment and then try to push that into the cluster. This works really good. In fact, we're going to see that today. But for smaller data sets, usually you want this option two.
You will need to use it for lookup tables to enrich the data of the main data set that you already have in Spark. This option two should be the last option that you should take. Option one should be always the first thing that you want to look at. You want to make sure that Spark ingests the data, not that R ingests the data.
You want to make sure that Spark ingests the data, not that R ingests the data.
This, like I said, not knocking down option two because it's very useful, like I said, to bring in more information, more meta information about your data, but shouldn't be your first choice.
Two things that Spark needs to read the data. Obviously, access to the data. And the second is a parser. So it needs to know how to read Redshift databases, how to read CSV files, how to read Hive data, how to read S3 buckets. So all that different parsers are usually handled via a package.
And when I say access to data, I'm going to switch back to this one right here. So when I say access to data, it means that every node in that cluster needs access to that data. This means, and which is kind of tricky because sometimes we may have a file that we bring into this node, but these two nodes cannot see the file, right? So when we try to load it into memory, it won't work because they don't have the same path to the file I have in the file introduced or uploaded to the one node. So that's why I mentioned here that for standalone mode, especially, a simple approach is to create a network share. So if you want to do a simple file that you want to have Spark read into memory without having to have an S3 bucket or if you don't have a data lake, then just use a simple network share. And I've done that, the Samba share, it makes the same path, relative path, the same amongst all the nodes in the cluster and you're able to ingest your data.
Demo: connecting to a YARN cluster
So let me, so I have some reference things here. We just released this new article and I'm going to talk to it here in a second. And also we have the standalone deployment in AWS, which is the one I mentioned that if you want to start getting acquainted with the deployment modes. And also this one, which I'll be updating by the end of next, this month. Yeah, next month.
So some of the stuff I'm going to do may be a little bit different than what you see in this article. And that's because I need to update it. But the main concepts are there about how to use S3 data with Spark.
So let's go to the demo here. Okay, so I'm running right now in a Hadoop cluster, it's a Cloudera cluster that has it has essentially four nodes, rights, and my name right here. And in that cluster, I have, I say physical details, you know, physical details, you know, so AWS is not really physical, but it's four worker nodes, they have 15 gigabytes of RAM, each have four cores. So obviously, we have a total of 16 cores, 60 gigs of RAM available. It's just a very small cluster. But hopefully, you'll see some of the examples here and how that would apply to your cluster.
There's two, three settings here. The two main ones are Yarn and Node Manager. We have Resource Memory and Resource CPU vCores. These are the two that may need to be updated in your manager, you know, whatever system you use to manage in this case, for their manager, you can make those changes in the actual setup. So this may be something that you need to work with your big data administrator.
And I talked about that in that article here, the deployment connections article that's mentioned here. Because usually, there's an error that occurs that the default is set pretty low, like eight gigabytes per executor. So if you ask for nine gigabytes, you'll see this error. And it tells you right there to go look at those settings. And these settings cannot be set in the configuration like we do here. Those settings can only be changed in the manager here or directly in the XML file for Yarn. So that's something very important to keep in mind.
So you can do the configuration changes by updating the Spark config. So you make a copy of that, and they make some of the changes. So one of the things that I mentioned here is that for your user configuration, start small and just build slightly bigger. So I've seen some configurations, I'm going to say that I mean, these configurations, that essentially look like, like this, like 20 lines before you even get to the connection. It makes all sorts of changes, and it's making no sense of what is being requested. So that is okay, if for whatever reason, that's what your environment needs. But if you're a new user that just trying to get some more, you know, performance out of your connection, try to start small, right? In this case, we'll just have executor memory, executor cores, instances, and the dynamic allocation, the same ones that are being proposed here in the article.
So you can always go back to here, and I can connect. So notice that I'm going to connect here. And all I'm doing is I'm requesting one gigabyte per executor, one executor core, and give me 10 instances. So because I'm under my threshold, obviously, of the 32 gigabytes, I'm going to expect it to give me 10 instances, because I have definitely more than 10 cores, and that's what I'm going to expect to see that return.
So we go to Hue, I got one job running, job number 26. I think that's it, let's see. There you go, 27. So I'm able to see this. So you'll notice that I got my 10 executors, right? And each one is giving me definitely like half of what I requested for the memory. That's because of the overhead that it's taking from my session, my requested session, and it's also... But it does give me all the executors that I asked for, right? So very important to see.
Going back to the point about that one node can have multiple executors. So this is a worker node. See this, it has the same IP address, but it has two different ports, right? And these are the ports to the actual executor. So here you can see that there's two executors in the same machine. So they're going to act as if they were their own little like virtual machines, but they're really both inside the same box.
This is important to also note that there is a balancing act that has to take place between how much resources you're giving each executor and how many executors you have. Because in this case, this is a very small cluster again. But when we talk about the larger clusters, the certain best practices that you need to approach it, you should use to approach it. So I would definitely recommend you going to this article. I have a link to a Nice Cloudera article where they discuss that and kind of explain how the resources are given and some of the best practices are talked about here. So I would definitely go back to that.
Working with Hive data and dynamic allocation
But note that we've got the resources that we wanted here. So I'm going to now send over just Spark flights. So I have a flight stable that's already in my cluster. So let me show you. It's already there. So I only have one Hive table that shows up here. And I just made a pointer to it. So the flights Spark, just a pointer to the table. And then I can do, you know, just a straight count. And it shows me that we have 42 million records in there. So several years of that flight's data.
That was a job that ran in the cluster here. So we can see the jobs. So ran four seconds. Usually, that takes a lot longer than that. So I'm just going to show you. Here. So we can see the jobs. So ran four seconds. Usually, that takes a lot longer. But because we're using a natural cluster, a lot faster. And I can do a count by unique carrier. It's a little bit longer. But you can see a job running here.
So I'm going to disconnect here. Another thing that I wanted to suggest is, like it mentions here, we need to give dynamic allocation a chance. So dynamic allocation, and it's also mentioned in the article, it's a way that Yarn can give you the resources that you need on demand, right? So if you're working on a cluster that other people are using as well, then you may want to consider this. That way, Yarn can decide to add or remove resources for your Spark connection as needed. And all you have to do to get it is essentially don't put any configuration. This is native to a Yarn implementation.
So you'll see, let me go to, that would be 28 now. This new job, I'm going to go to executors. Notice that I have no executors, which is very unnerving, especially the first time I used it, because I'm so used to seeing my executors already listed. And when they're not listed, something's wrong, right? So here, I can go ahead and I'm going to cache the entire flights table. And then I'm going to equate it to this variable. So when I cache it, it should start using resources from the executors.
So you see that there, all of a sudden, now we have active tasks. So it automatically started creating the executors for me, and it created a bunch of them, trying to get all of my tests done. So it was able to do the job in basically 23 seconds. I got my flights table cached. And of course, this is going to run a lot faster once it's in memory, right? So you saw how the executors just basically started appearing automatically, which is great, especially if, like I said, if you're sharing this server, this Flickr cluster, and also if you're new to Spark, you can start without any settings and in any way. You can start without any settings and in a data lake for using Yarn client. And I would say that that should be like the first thing you should try.
Loading data from local and S3 sources
Since we're connected, I want to talk about going back to the deployment and creating data. So we have the two things. Right now, we told Spark to go get the data from Hive and load it into memory. The other thing that we can do is to get it to read data from our local machine, right? So I got a little error there. So let me show you here. So it says Spark read CSV. We want to read the plain CSV file, right? Which is right here. So if I run this, I actually expect it not to work. So I'm going to run that and see it fail. And the reason it fails is because Spark read CSV is not reading against your home directory in R. It's actually reading against your cluster.
So you'll notice that if I were to show you in Q, my files here. I don't have a planes.csv. I have an airports.csv and we're going to use that in a minute, but not a planes.csv, right? So if I want to get planes into my Spark environment, I essentially have two options, right? I either take the planes.csv file and use Q or something to upload it to my cluster. Or I do what we talked about in option two, essentially load into our memory and then put it in Spark, which is what I'm doing here. So I'm going to read it into memory using read R. And then I'm going to use copy to send it over to my environment. Now that it's in the environment, now I can do a join. And it works just like a regular Dplyr or SQL, however you would like to see it. But now I'm able to do something like this, where I can, in the planes I have a manufacturer. So I can do how many flights per manufacturer. So now I combine the two tables in there. You saw that in order for me to do that, I have to send it over using this option. And as probably you can tell, it's not the best option if this file will be huge. That's why if this file would have been in my opinion over one gigabyte, I would have used Q and just upload it here and read it right off the HDFS, which we're going to do here in a minute.
Okay, so moving on, another cool thing that I want to show you is same here. So we were using Hive and of course, Hive is a big part of Yarn. So in Spark and Hadoop, they're all these very interconnected technologies. So I wanted to do something remote. So we're going to do S3. So I'm going to load my access key for S3, which is going to be S3. Which is that article I was talking about, AWS with S3. And then I'm going to, I'm going to stop this for now. And I'm going to start a new configuration. So I'm going to request four cores. Actually, let me change this to five. I don't need that much. So five gigabytes, which will give me 20 gigabytes and four, four, actually, all right, and four cores. They're each give me an entire setup.
And this is the important piece. The default packages is where I tell Spark what package to use during its, while it's running. And in this case, this Hadoop AWS is the one that we need to run to, for it to be able to parse S3 bucket files. So I opened the connection and that should create a new one here.
Okay, so 16 cores and 17 gigabytes. It's not bad. And that's my spot. Okay. And now this is really cool. So I can tell the path on the Spark read CSV. I'm telling Spark to go to this path. And this path right here, S3A flights data full is this right here. So I have an S3 bucket in this full folder. I have these CSV files, right? And see how big they are. So what I'm going to do is I'm pointing Spark to where the data source is. And I'm telling it to go ahead and don't bring it into memory yet. And don't refer to schema. I'm going to give you what the schema is. And just go ahead and essentially map it. So that's what my executors are going to do.
So it's done. You see that it was a very light job. It's just basically going over to S3 and confirming that what I'm telling it is there. And now, oh, and another thing. I also mentioned that in the first webinar. You notice that I don't put the file names here. I just put in a path, right? And what the trick here is that every single file in here has the same layout. So it's being used just like it would be in Hive if you're related to, if you are aware of how it works in Hive that you have multiple files. But all of them should have the same layout. So they're all considered one big file.
So the next thing I'm going to do is I'm going to cache some of the data. And I'm using compute. So now I can see in storage as the data gets cached. So you see as it's caching. And now we're going to use this data. Once it's fully cached, we're going to go and do some more work with it. So hopefully you see that I'm talking about how to load data and how to do some tuning to better deploy not only new environments, but also your user configurations so they can be tuned in a better way.
So now we're going to use Spark CSV to get the airports.csv file, which is the other file I have here. So that is in HDFS. So I'm able to say, get it from there. Just going to go directly into my Spark context. And from there, I can join it. And now I can do some analysis with it. I can get like the top busiest airports. But now we have the names instead of just the code.
Another thing that is nice to have in the airports file is the longitudinal latitude. Right? And since I'm able to join it to the large 42 million record table, then I can do this. I can take the joint table and then get the longitudinal latitude and name and group it by it, get how many flights happened, and then give me the top 1000. So this is the top 1000 airports and how many flights they have.
And then I have here, I can run a visualization, for example. So I can map them because there's so many. You'll see that it actually shows your shape of the US already. And what I did is I had the colors in as well as the size. So it's very easy to see where Atlanta is, where Houston is, Chicago. So you see, very easy to visualize. And I used to collect to get the data back into our memory. And until now, we have some data as a data set. But you see that we're not getting anything anywhere near to what we would, the amount of data that we're working with inside.
dbplot and persisting data with Spark write table
Last thing I want to show you is this new package I've been working on called dbplot. There's a new thing that new feature of it where you can actually run a box plot. So you can definitely do it manually. You can look at the code if you like. But it's really nice because actually box plots are very paralyzed. So run much faster than it would if we were to bring the data back into memory. So what I did here is I took the top list, which represent, I think, like at least 50%. So maybe 20 million records. And I'm doing a box plot over those top 20. And then the distance. So you saw that it ran pretty fast. And all I had to do was to call the box plot. So maybe something that you want to consider looking at.
I just made a change recently for it to support older versions of Hive. So if you tried it before and it didn't work, just know that it does work now. I have a quick appendix down here that talks about creating a new Hive table, which is how I actually got the Hive metastore loaded with the flights table here.
So something that we don't talk about much is this function right here. Spark write table. If you're working on a Spark and Hive cluster managed by Yarn, and if you want to persist data, because you know, as soon as I close my connection here, my data is gone, right? And I've had some folks ask questions about, okay, what if I want to keep the data? You know, usually you would like create a large file and put in HDFS and then something else with it. But normally what we want to do is to go back and analyze it later. You can do Spark write table and take the Spark data frame and then give it a name. And that's the name that ended up here. And what it does in the background, it creates not only the actual mapping and all that, but also does the partition for us. So it creates a bunch of smaller parquet files and saves them into the warehouse folder. So a really nice function. I don't think we talked about it too much, but if you're in a Yarn environment, this would definitely be of advantage.
Standalone cluster demo and memory fraction
So I'll show you, this is the standalone cluster. So I did the same thing and this was going to be part of the original demo. But I do want to show you real quick here, the standalone cluster. And if I were to do a connection here. So I'm going to, in a Spark standalone, to go to the actual location, which your job is, because there's only one job from the driver. You can just switch from the same URL, but to port 8088. Oh, excuse me, port 40. Sorry, port 40. And that will show you here all the jobs. And I can show you here the executor page.
Something about the executor page is that the course will always be managed by the master and will always be regarding how many actual servers you have. So it's very rare when we're going to need more than one executor per node. And it's kind of hard to set it up unless you start manipulating the dynamic allocation and the number of course to be lower than what's available in the server, in the worker node. So again, you'll notice that all these are the same except the memory fraction. You actually have control over that. So I'm going to close this real quick and reopen it.
So memory fraction will actually give me closer to the seven gigabytes because I'm setting it to 90%. And if I go back here, so you see it gives me 35 gigabytes, which is the, I said, give me two. So I'm going to reopen it here. And I'm going to say, yeah, 90%, what I'm asking for. So if I were to change this to 30%, for example. And then push here. And you notice that now it's much slower. And that's because the fraction is something that you can control. It's a big point that if you're going to be doing some standalone, it's also mentioned in the article, consider moving the memory fraction a little bit too, if you need more space in your cluster.
Wrap-up
So just to kind of do a quick review, I'm going to go back to here. If you have, this is to me the key item for today. If you had data load options and questions, definitely think about these two options, right? And always try to load the data from the remote source directly into Spark. And always consider the option to be more of a, just for smaller tables, as well as a last resort if you don't, not all of the nodes have access to the same data source. Okay, so that's all I have. And thank you.
We have a new door that's open to us with Spark VR as data analysts. The way that Spark VR approached this has helped us to be able to use Spark VR in a very effective way. And the other thing that tells me is the fact that we're having webinars and really promoting it and also developing it, it's just supposed to show that our commitment to make it even better for everyone, I think that says a lot as well.
So I know that natively, Spark really only works with Hive. So there may be a way to get some HBase connectivity, but I haven't worked with it myself. That's something that is interesting for us to look at. We also have a separate effort to start doing more support of different data sources directly into R through the data connections tab that is new. You notice that it's not called Spark anymore. And HBase is one of the ones that we're going to test. So I'm sure we're going to have some documentation about that here soon.