


In this technical post, we’ll dive into some performance improvements we’ve made to dplyr 1.2.0 to make if_else()
and case_when()
up to 30x faster and use up to 10x less memory.
If you haven’t seen our previous post about the exciting new features in dplyr 1.2.0, you’ll want to go check that out first!
Here’s a before-and-after benchmark with if_else()
:
# Using https://github.com/DavisVaughan/cross
cross::bench_versions(pkgs = c("tidyverse/dplyr@v1.1.4", "tidyverse/dplyr"), {
library(dplyr)
set.seed(123)
condition <- sample(c(TRUE, FALSE, NA), size = 1e7, replace = TRUE)
x <- sample(10, size = 1e7, replace = TRUE)
y <- sample(10, size = 1e7, replace = TRUE)
z <- sample(10, size = 1e7, replace = TRUE)
bench::mark(if_else = if_else(condition, x, y, missing = z))
})
|
|
And with case_when()
:
cross::bench_versions(pkgs = c("tidyverse/dplyr@v1.1.4", "tidyverse/dplyr"), {
library(dplyr)
set.seed(123)
column <- sample(100, size = 1e7, replace = TRUE)
x_condition <- column < 20
y_condition <- column < 50
z_condition <- column < 80
x <- sample(10, size = 1e7, replace = TRUE)
y <- sample(10, size = 1e7, replace = TRUE)
z <- sample(10, size = 1e7, replace = TRUE)
bench::mark(
case_when = case_when(
x_condition ~ x,
y_condition ~ y,
z_condition ~ z
)
)
})
|
|
So a 33x speed improvement for if_else()
, a 15x speed improvement for case_when()
, and a 10x improvement in memory usage for both! In the rest of this post, we’ll explain how we’ve achieved these numbers.
Let’s talk memory#
We’ll start with case_when()
, because if_else()
is actually just a small variant of that.
The most important place to start is with the memory usage. Memory usage and raw speed are often related, as allocating memory takes time. Let’s look at the memory usage of case_when()
in dplyr 1.1.4:
set.seed(123)
column <- sample(100, size = 1e7, replace = TRUE)
x_condition <- column < 20
y_condition <- column < 50
z_condition <- column < 80
x <- sample(10, size = 1e7, replace = TRUE)
y <- sample(10, size = 1e7, replace = TRUE)
z <- sample(10, size = 1e7, replace = TRUE)
|
|
That’s a lot of allocations! And it’s pretty hard to understand where they are coming from without a bit more explanation. For that, we’re actually going to “manually” implement an underpowered version of case_when()
for this example.
Here’s a diagram of what we need to accomplish:
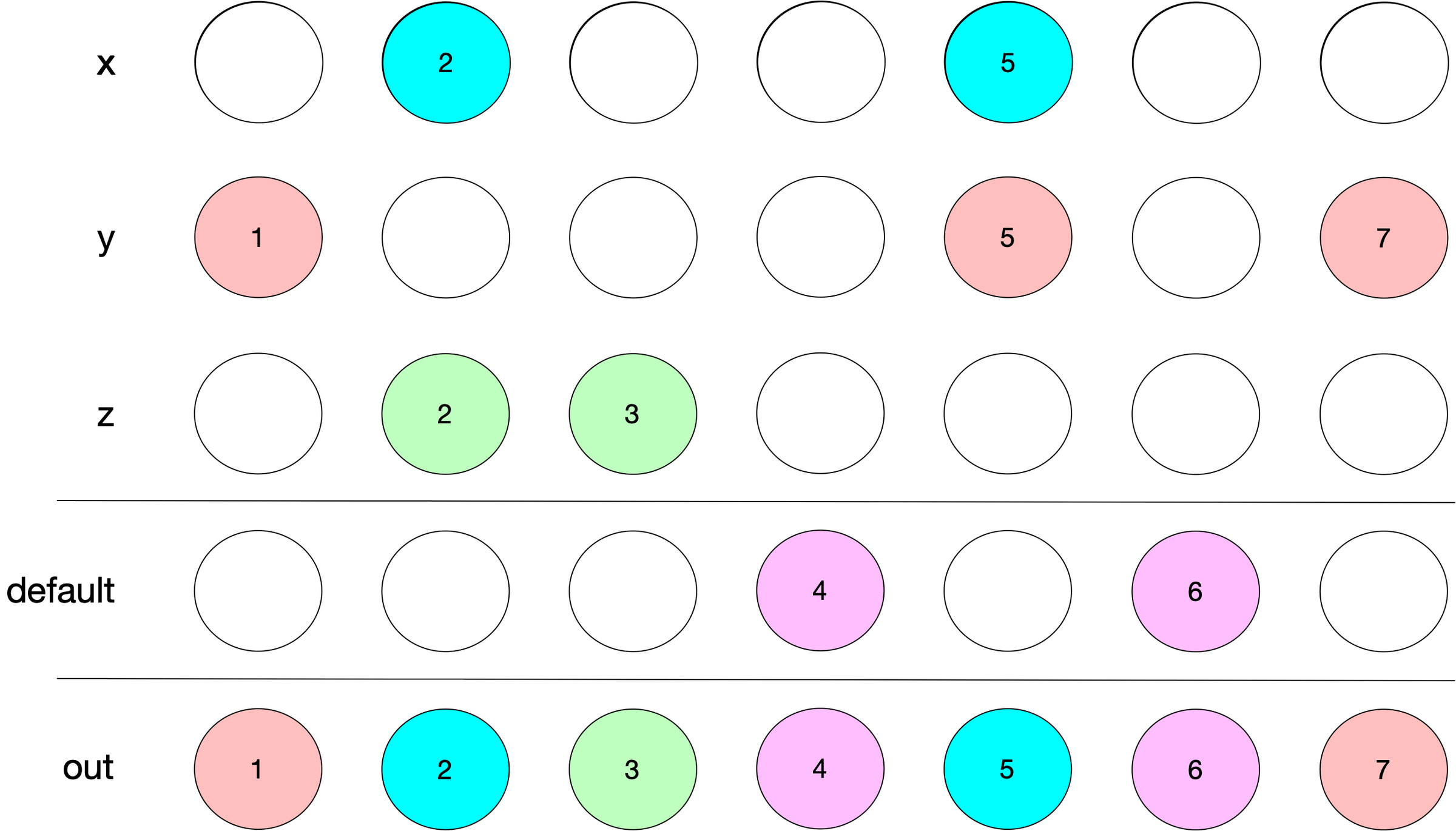
In bullets:
x_conditionselects the blue elements ofxy_conditionselects the red elements ofyz_conditionselects the green elements ofz- A
defaultis built around the unused locations - We combine all of the pieces into
out
The trickiest part about case_when()
is handling places where x_condition and y_condition overlap. In the image, even though both x and y are selected at location 5, only the value of x is retained since it is hit “first”. This forces us to have to modify y_condition to avoid already “used” locations.
An R implementation that computes these modified locations might look like:
n <- length(x_condition)
unused <- rep(TRUE, times = n) # 1
x_loc <- unused & x_condition # 2
x_loc <- which(x_loc) # 3,4
unused[x_loc] <- FALSE
y_loc <- unused & y_condition # 5
y_loc <- which(y_loc) # 6,7
unused[y_loc] <- FALSE
z_loc <- unused & z_condition # 8
z_loc <- which(z_loc) # 9,10
unused[z_loc] <- FALSEAnything that is still unused falls through to the default:
default <- NA_integer_
default_loc <- which(unused) # 11,12With x_loc, y_loc, z_loc, and default_loc in hand, we can build the output from the pieces:
out <- vector("integer", length = n) # 17
out[x_loc] <- x[x_loc] # 13
out[y_loc] <- y[y_loc] # 14
out[z_loc] <- z[z_loc] # 15
out[default_loc] <- rep(default, times = length(default_loc)) # 16And sure enough, this is identical to case_when()
:
You might be wondering what all of the comments with numbers beside them mean. Those actually map 1:1 with the allocations that case_when()
was emitting. In fact, we can now split up those allocations into their respective role:
|
|
We sought to remove every one of these allocations except for the last one, which is the final output container that is returned to the user. In other words, we were after this, which is the actual profmem result of this case_when()
call in dplyr 1.2.0:
|
|
Sliced assignment#
To work towards this, let’s focus on what happens to x throughout this process:
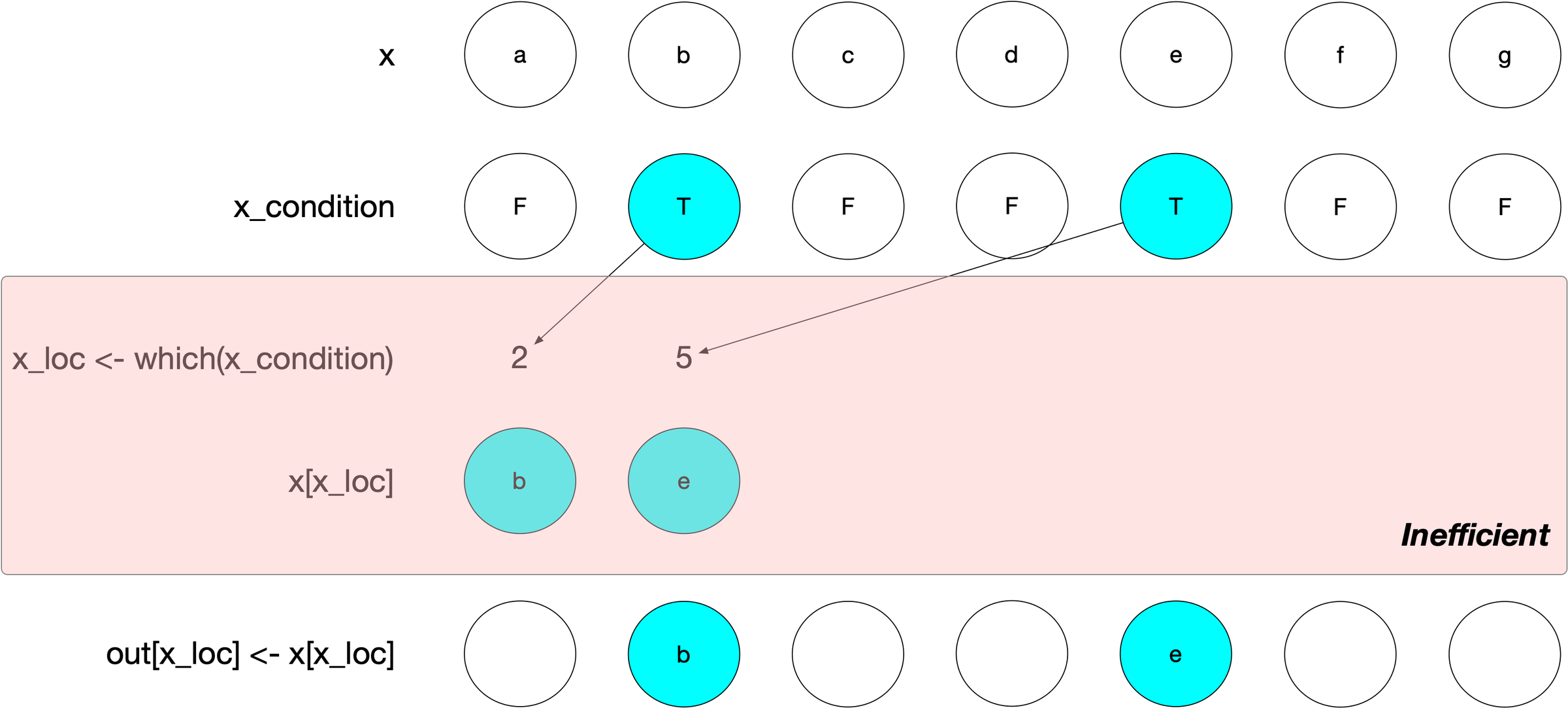
We had a hypothesis that we could cut out the intermediate work here. Ideally, we’d take the logical LHS x_condition and the RHS x and map that straight into the output, with no extra allocations:
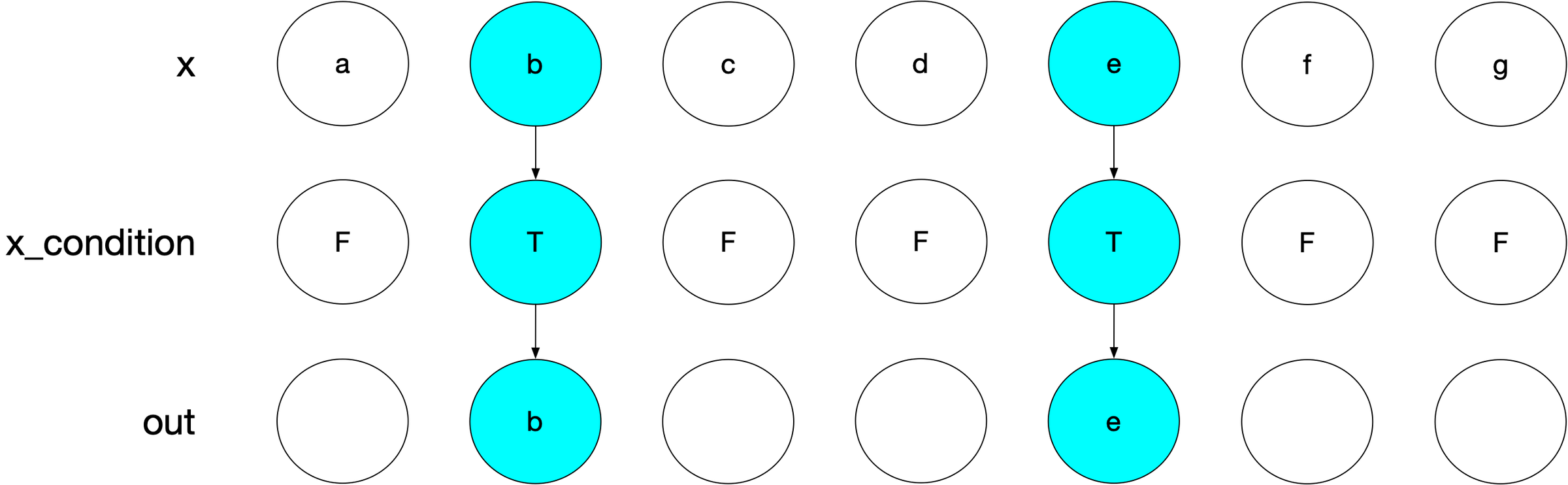
But this just wasn’t possible with the way that assignment typically works in R!
x <- c("a", "b", "c", "d", "e", "f", "g")
x_condition <- c(FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE)
out <- vector("character", length = length(x_condition))
out[x_condition] <- x
#> Warning in out[x_condition] <- x: number of items to replace is not a multiple of replacement length
Instead, you must pre-slice x to a length that matches the locations that x_condition points to in out, i.e.:
out[x_condition] <- x[x_condition]Now, in case_when()
we don’t actually use [<- for assignment or [ for slicing. Instead, we use tools from vctrs
, a low level package for building consistent tidyverse functions. In this case, we’d use vctrs::vec_assign() and vctrs::vec_slice():
out <- vctrs::vec_assign(out, x_condition, vctrs::vec_slice(x, x_condition))But vec_assign() had the same problem!
To solve this, we’ve added a new boolean argument to vec_assign() called slice_value. You use it like this:
out <- vctrs::vec_assign(out, x_condition, x, slice_value = TRUE)With slice_value = TRUE, vec_assign() assumes that both out and x are the same length and that x_condition applies to both of these. Internally, rather than materializing x[x_condition], we instead just loop over both out and x at the same time (at C level) and copy over values from x whenever x_condition is TRUE.
This is huge! It means that allocations 13-15 from above related to slicing x, y, and z all disappear.
Logical indices#
You might have noticed that we’ve been using which() quite a bit in the above algorithm. This turns a logical vector of TRUE and FALSE into an integer vector of locations pointing to where the logical vector was TRUE:
x_condition <- c(TRUE, FALSE, TRUE, FALSE, FALSE, TRUE)
x_loc <- which(x_condition)
x_loc
#> [1] 1 3 6
We perform this conversion up front due to how the following works at C level:
out[x_condition] <- x[x_condition]Both [ and [<- will convert a logical x_condition into the integer x_loc form before proceeding with the assignment, meaning that which() gets called twice if we don’t do it once up front. And vctrs is the same way! Both vec_assign() and vec_slice() here would convert x_condition to an integer vector.
vctrs::vec_assign(out, x_condition, vctrs::vec_slice(x, x_condition))Now, with the previous optimization we’ve already seen that we can reduce this to:
vctrs::vec_assign(out, x_condition, x, slice_value = TRUE)But vec_assign() still converts a logical x_condition to integer locations internally before doing the assignment. So now it doesn’t matter whether we do this conversion up front via which() or if we let vec_assign() do it, it still happens once per input. But we’d like to avoid it entirely!
The solution here wasn’t too magical, it just involved a good bit of grunt work. We’ve added a path in vec_assign()’s C code
that can handle logical indices like x_condition directly, rather than forcing them to be converted to integer locations first.
But this is a huge win, because it means that allocations 1-10, which were all related to which()
, can now be removed. vec_assign() will just handle that optimally for us without any extra allocations.
The nice part about an optimization like this is that any other existing code that is using vec_assign() with a logical index will also benefit from this without having to change a thing!
default handling#
The remaining allocations are 11-12 and 16, which all have to do with the implied default. Allocations 11-12 were about figuring out where to put default, and allocation 16 was about recycling a typed size 1 default to the right size before assigning it into out.
As it turns out, we don’t need any of this!
In vctrs, when we initialize any output container, we use vec_init():
vctrs::vec_init(integer(), n = 5)
#> [1] NA NA NA NA NA
vctrs::vec_init(tibble(x = integer(), y = character()), n = 5)
#> # A tibble: 5 × 2
#> x y
#> <int> <chr>
#> 1 NA NA
#> 2 NA NA
#> 3 NA NA
#> 4 NA NA
#> 5 NA NA
This already has the implied default assigned to every location. We then overwrite this with x, y, and z at the appropriate locations, but anything left untouched by those is still set to the default, so we’re done!
For cases where the user supplies their own default, things are slightly more complicated. We actually do have to compute a default_loc implied from x_condition, y_condition, and z_condition, but internally we do so using a C vector of bool (even more efficient than R’s logical vector type), so the memory footprint is as small as it can be.
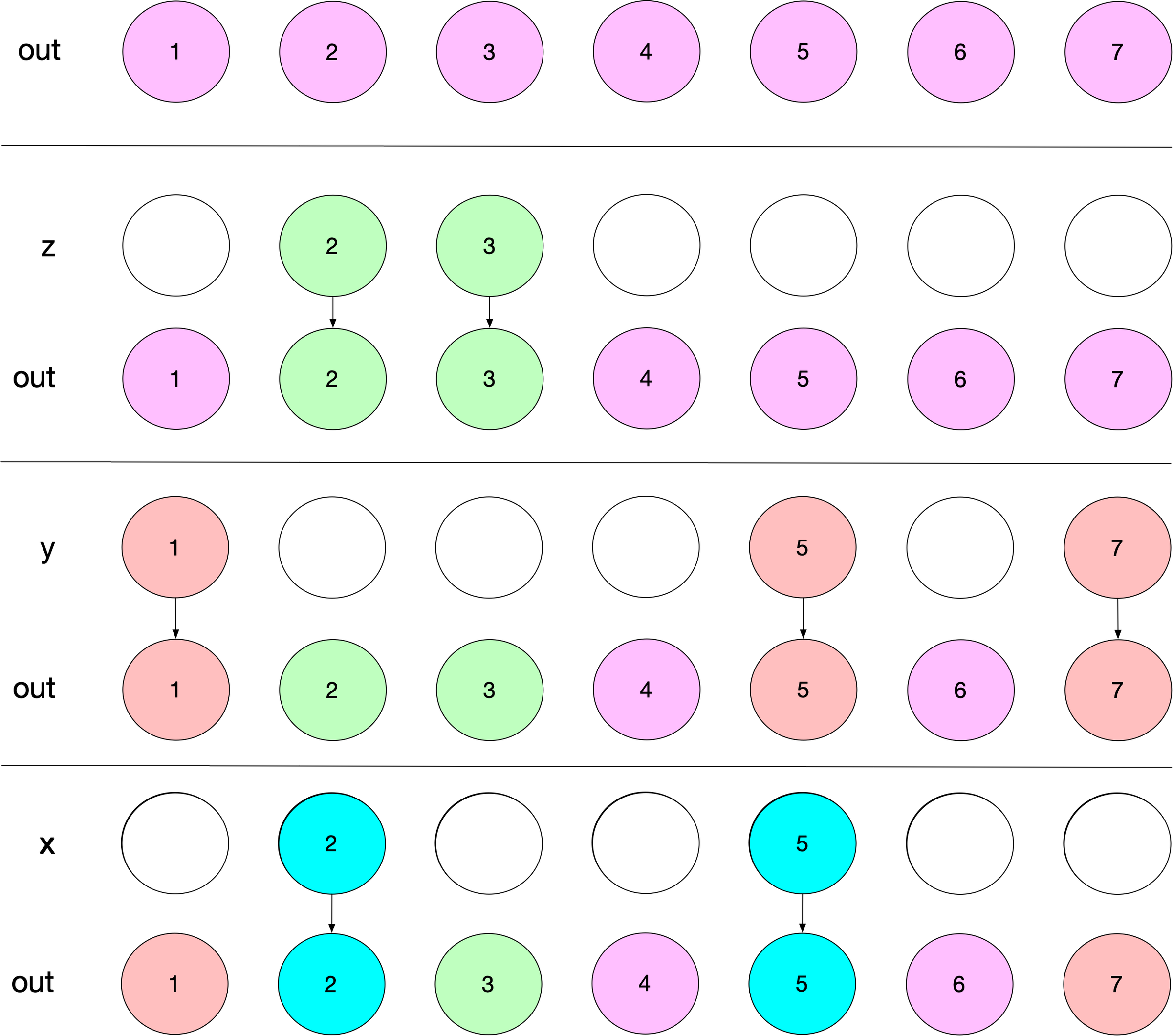
The “first wins” conundrum#
One thing we’ve skipped over is the “first wins” behavior of case_when()
mentioned earlier. Now that we’ve removed x_loc, y_loc, and z_loc, which is where that was being handled, how do we keep this behavior without slowing things down?
To be explicit, we are talking about this feature of case_when()
where only the first hit is kept when you have overlapping logical indices:
x <- c("x1", "x2", "x3")
y <- c("y1", "y2", "y3")
z <- c("z1", "z2", "z3")
x_condition <- c(TRUE, FALSE, TRUE)
y_condition <- c(TRUE, TRUE, FALSE)
z_condition <- c(FALSE, TRUE, TRUE)
case_when(
x_condition ~ x,
y_condition ~ y,
z_condition ~ z
)
#> [1] "x1" "y2" "x3"
A naive approach doesn’t work, as you end up with “last wins” behavior:
out <- vctrs::vec_init(character(), n = 3)
out <- vctrs::vec_assign(out, x_condition, x, slice_value = TRUE)
out <- vctrs::vec_assign(out, y_condition, y, slice_value = TRUE)
out <- vctrs::vec_assign(out, z_condition, z, slice_value = TRUE)
# This is wrong!
out
#> [1] "y1" "z2" "z3"
identical(
out,
case_when(
x_condition ~ x,
y_condition ~ y,
z_condition ~ z
)
)
#> [1] FALSE
Instead, case_when()
just iterates in reverse, assigning z, then y, then x:
out <- vctrs::vec_init(character(), n = 3)
out <- vctrs::vec_assign(out, z_condition, z, slice_value = TRUE)
out <- vctrs::vec_assign(out, y_condition, y, slice_value = TRUE)
out <- vctrs::vec_assign(out, x_condition, x, slice_value = TRUE)
identical(
out,
case_when(
x_condition ~ x,
y_condition ~ y,
z_condition ~ z
)
)
#> [1] TRUE
This diagram demonstrates how that works:
Optimizing speed?#
Now that we’ve optimized the memory usage of case_when()
, you might be wondering if we did anything else to specifically optimize its speed. Not really! We have moved everything from R to C, but focusing our efforts on reducing memory also resulted in some pretty performant code, and there wasn’t much left to optimize after that.
if_else()#
if_else()
can actually be written as a form of case_when()
:
if_else(condition, true, false, missing)
case_when(
condition ~ true,
!condition ~ false,
is.na(condition) ~ missing
)In our actual C implementation of if_else()
, for simple types like integer, character, or numeric vectors we have an extremely fast path
that’s even more optimized than this, but for anything with a class we pretty much use this exact case_when()
approach.
For package developers#
If you’re a package developer, you’ll be happy to know that vctrs itself now exposes low dependency versions of if_else()
and case_when()
, here’s the full family:
vec_if_else()vec_case_when()vec_replace_when()vec_recode_values()vec_replace_values()
dplyr::if_else()
and friends are now just very thin wrappers over these. Feel free to use the vctrs versions in your package if you need the consistency of the tidyverse without the heavy-ish dependency of dplyr.
At the deepest level, list_combine()#
At the deepest level of all of this is one final new vctrs function, list_combine(). This is a flexible way to combine multiple vectors together at locations specified by indices.
list_combine() powers all of vec_case_when(), vec_replace_when(), vec_recode_values(), vec_replace_values(), vec_if_else(), and even vec_c(), the tidyverse version of c()
.
set.seed(123)
column <- sample(100, size = 1e7, replace = TRUE)
x_condition <- column < 20
y_condition <- column < 50
z_condition <- column < 80
x <- sample(10, size = 1e7, replace = TRUE)
y <- sample(10, size = 1e7, replace = TRUE)
z <- sample(10, size = 1e7, replace = TRUE)
out <- vctrs::list_combine(
x = list(x, y, z),
# `indices` are allowed to be logical and aren't forced to integer
indices = list(x_condition, y_condition, z_condition),
size = length(x_condition),
# When there are overlaps, take the "first"
multiple = "first",
# Same as `slice_value` from `vec_assign()`
slice_x = TRUE
)

