


You love data. And you love building dashboards with it, especially with your favourite tool Shiny. But even with a bullet-proof design, dozens of user stories, feedback loops, and adjustments, you also know that there are always questions that your dashboard leaves unanswered.
Let’s say you developed a dashboard to display women’s international soccer matches. You are proud of what you have built and you eagerly show it to a colleague:
Colleague: “Amazing! Can you show me the soccer matches for the FIFA World Cup only?”
You: “Of course, let me filter it down for you and select the FIFA World Cup tournaments”
Colleague: “Interesting, can you show me all the matches in which The Netherlands have played?”
You: “Eh… Well, I could, but I just have to include a country filter in my dashboard then!”
Right. How are we supposed to filter down to a specific country if there is no input for it? And what about getting summary statistics for countries or players? By now it becomes painfully clear that our soccer dashboard has its limits.
This is exactly the moment when querychat
becomes interesting. It is a multilingual package that allows you to chat with your data using natural language queries. No more clicking, no more limited filters, just you and your questions. And in this article, you’re going to learn everything about it!
To bring querychat to life, we will keep returning to two examples:
- The classic diamonds dataset. After all, diamonds are a girl’s best friend, and a data scientist’s too! The familiar dataset offers a mix of variables such as cut, colour, clarity and price, which makes it ideal for all sorts of natural language questions. You might wonder about average prices for particular cuts, or you want to compare colours, look at how clarity affects value, or explore simple patterns in the data. In other words, it is a perfect playground for testing how well natural language queries behave on structured data.
- SheScores, the soccer dashboard that you were so proud of earlier. This app originates from the shiny::conf(2024) workshop “Shiny 101: The Modular App Blueprint” , although it has been tweaked to make it a bit more interesting and updated with matches through to November 2025.
Python#
R#
Both datasets set the stage nicely, so let’s roll the ball and see how querychat plays. We’re talking about soccer after all!
Full code available on GitHub
Instead of copy-pasting the content of this blog into your favourite IDE, you can also pull the project from GitHub and follow along. All the code is available in both Python and R.
Short on time?
Jump straight to the SheScores app with querychat or visit the querychat website
Hello, querychat#
In short, querychat makes it easy to query data using natural language. It offers a drop-in component for Shiny, a console interface, and other programmatic building-blocks. You ask questions, querychat translates it to a SQL query, executes it, and returns the results. The results are available as a reactive data frame, which makes it easy to display or further process the data.
querychat would solve the problem we encountered earlier. We can ask it any question we can imagine without constantly adding filters or other analysis. No country filter? No problem. And yes, that sounds as cool as it is!
So, what do we need?
querychat is powered by a Large Language Model (LLM), so you need access to a model. You first need to register at an LLM provider that provides those models. You can choose any model you like, with two little “restrictions”: chatlas
(Python) or ellmer
(R) supports it (which shouldn’t be hard, because all the major models are) and the model has the ability to do tool calls.
Recommended models
In this blog we’ll use Claude Sonnet 4.5 from Anthropic. Other good choices would be GPT-4.1 (the current default for
querychat) and Google Gemini 3.0 (as of November 2025).
Once you’ve made your choice and registered, you can get an API key. You need this key to authenticate with the LLM provider. One important note: never, ever hardcode the key directly into your script. You’ll be amazed how many keys are publicly available on GitHub repos. Don’t be that developer. As always with secrets, store it as an environment variable. Just note that the exact name of the key depends on the provider. For example, Anthropic expects ANTHROPIC_API_KEY=yourkey, while OpenAI uses OPENAI_API_KEY=yourkey.
Python#
In Python, the recommended approach is to create a .env file in your project folder:
|
|
It’s recommended to use the dotenv package to load the .env file into your environment:
|
|
To keep the demo code concise we’ll omit these lines from subsequent code examples.
R#
In R, environment variables are typically stored in a .Renviron file. You can create this file in your project root or in your home directory (~/.Renviron). Or, if you want to make it yourself really easy: you can also open/edit the relevant file with usethis::edit_r_environ().
|
|
Of course we can’t use querychat without installing it, so that’s the next step:
Python#
For Python, querychat is available on PyPI, so you can install it easily with pip:
|
|
Or, if you’re using uv, add it like so:
|
|
Once installed, import it like this:
|
|
R#
You can get querychat from CRAN using:
|
|
Alternatively, if you want the latest development version, you can install querychat from GitHub using:
|
|
Once installed, load the package as usual:
|
|
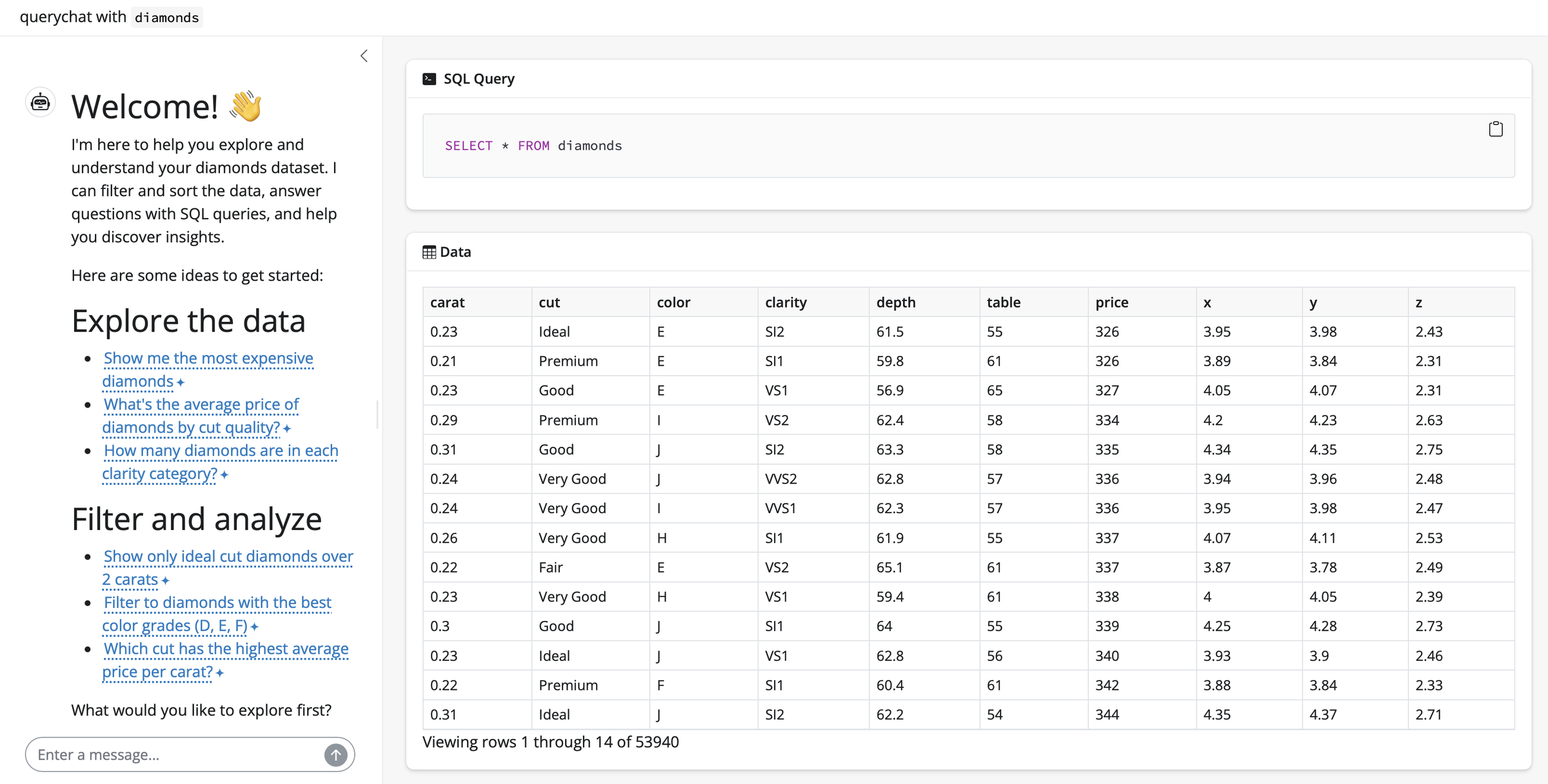
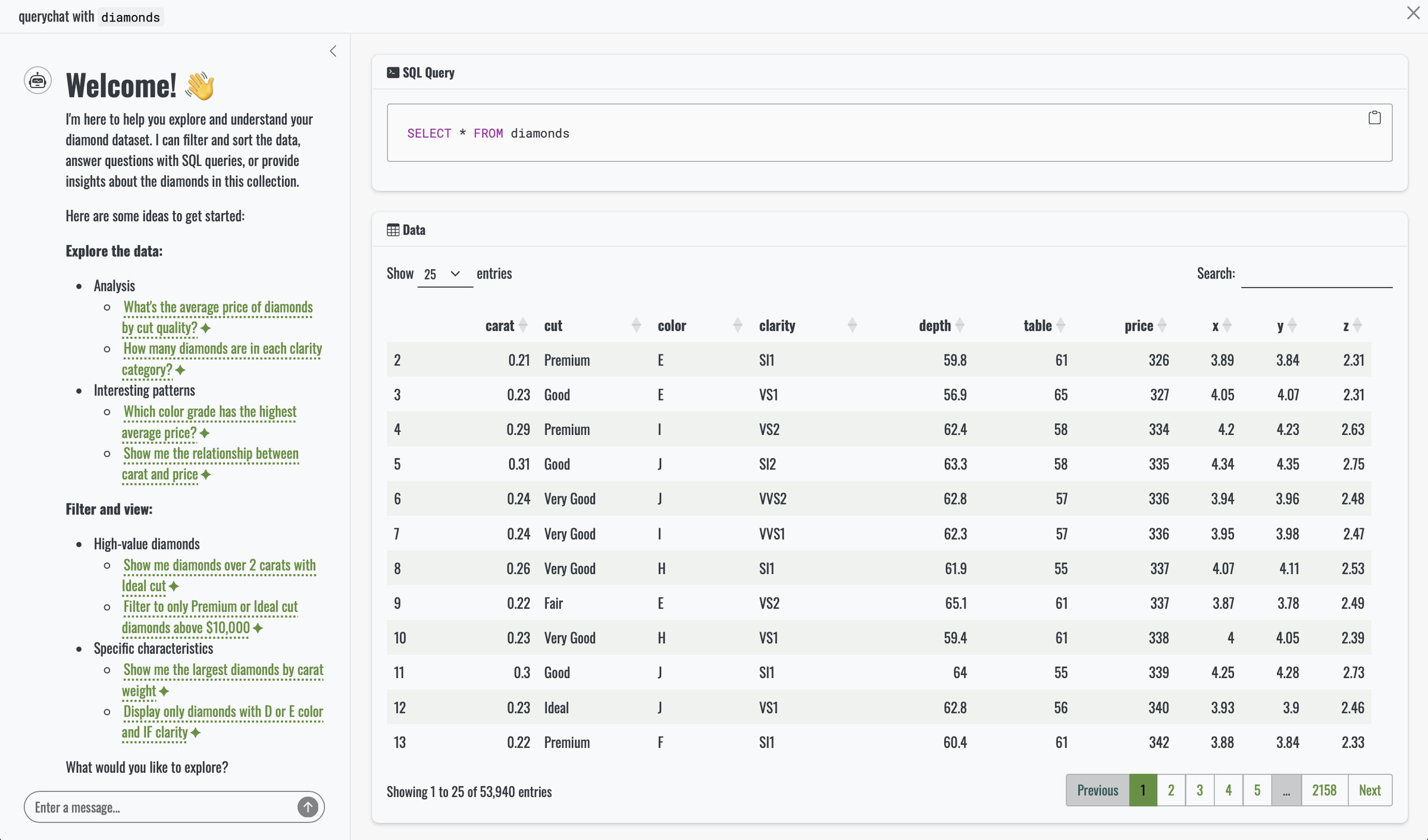
Wouldn’t it be great if you can use querychat straight away without much code? Just to see what it’s all about? Luckily you can with the “quick launch” Shiny app! You can simply call app() which spins up an app with querychat chat interface. Let’s try it out for our diamonds dataset:
Python#
|
|
qc = QueryChat(...) creates an instance of the QueryChat class. You pass in the dataset, give it a name and specify the model client (powered by chatlas
). qc.app() returns the web app that lets you explore the diamonds data using natural language questions.
Want to try this with a different provider and/or model? No problem, just change the client argument accordingly. For example, to use GPT-4.1 from OpenAI, you would write: client="openai/gpt-4.1". You can learn more about the different options in the querychat documentation
.
To run this app, you need to save the code above in a file (and call it diamonds-app.py
for example) and run it like so:
|
|
R#
|
|
Or, alternatively, you could write:
|
|
Both result in the same outcome, the first one is just a simplified version.
QueryChat$new() creates the R6 object, taking the dataset, a table name and the model client (which will be passed to ellmer::chat()). Calling qc$app() then launches the Shiny app so you can query the diamonds dataset in plain English.
Want to change the provider and/or model? No problem, just change the client argument accordingly. For example, to use GPT-4.1 from OpenAI, you would write: client = "openai/gpt-4.1". You can learn more about the different options in the querychat documentation
.
The result: a Shiny app that allows users to interact with a data source using natural language queries.
Python#
R#
Custom branding
Do you notice the nice green touches and custom font in this demo app? That’s because the project we’ll be using in this article uses brand.yml : a simple, portable YAML file that codifies brand guidelines into a format that can be used by Quarto, Python and R. And in this case, it works beautifully for Shiny. Curious to see what such a
_brand.ymlfile looks like? You can check it out here .
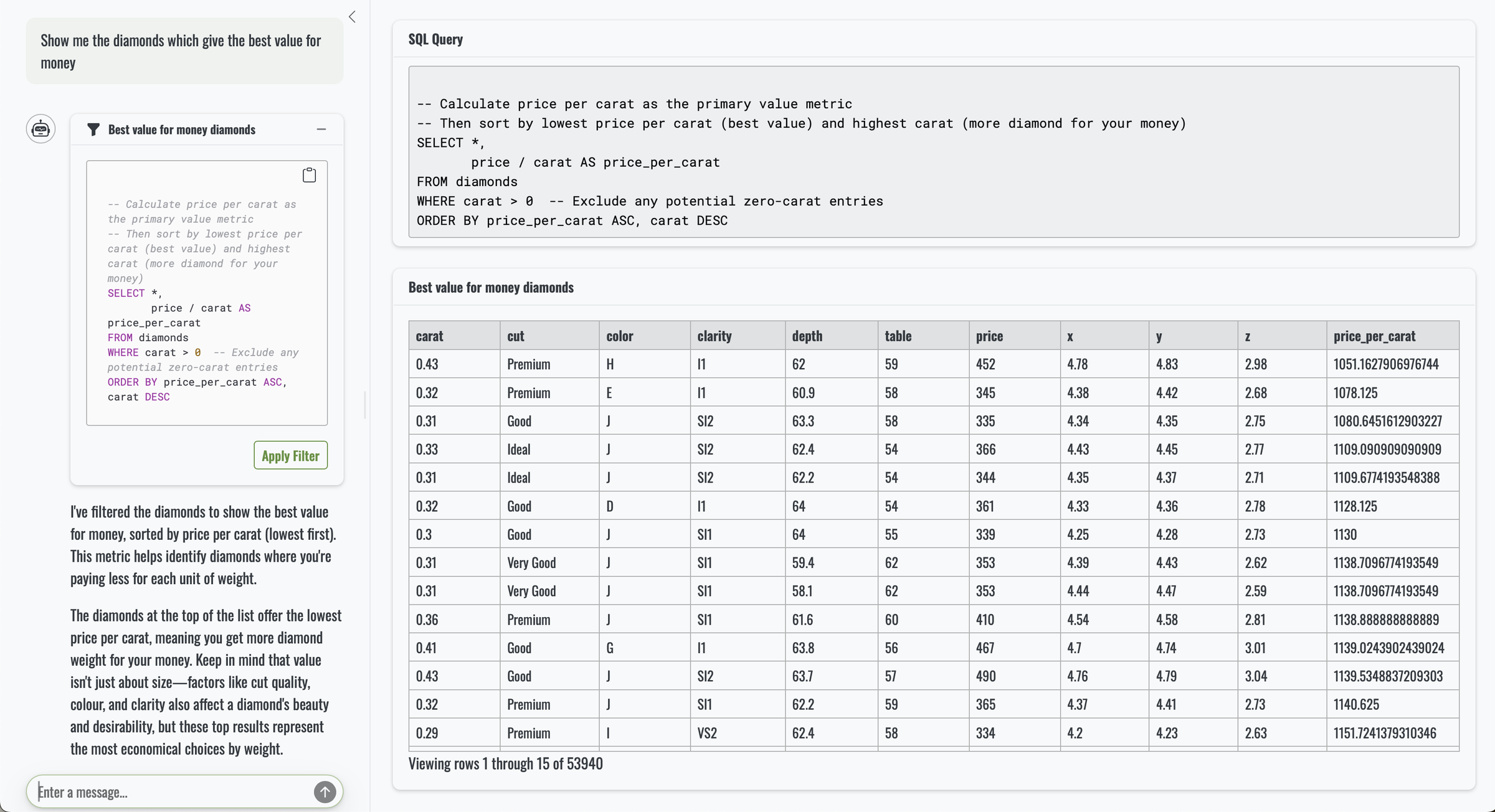
You can ask the diamonds dataset some surprisingly rich questions, and querychat handles them with ease. A simple place to begin is something like “show the 10 most expensive diamonds”. It produces straightforward SQL and updates the table in the app instantly.
|
|
The question may be simple, but it already highlights the convenience of querychat. Without it, users would need to sort the table manually or rely on a picker, slider or some other input that filters the data for this very specific request.
Things get more interesting when we introduce a calculation. Asking “can you show the 20 biggest diamonds, based on volume?” still results in simple SQL, but the output now includes an extra column, volume, which appears neatly in the app.
|
|
From there, we can try some grouping and window functions. “Within each cut, what is the most expensive diamond?” works perfectly, showing the grouped results along with the necessary window function behind the scenes.
|
|
|
|
Now, for a grand finale, we can throw in a more analytical question: “are larger physical dimensions always associated with higher price?” This one generates a slightly more complex SQL query, but it also comes with a clear and helpful explanation.
|
|
|
|
The conclusion?
|
|
To encourage further exploration, querychat presents suggestions such as comparing how cut quality affects the price to carat ratio, finding diamonds where clarity has the biggest impact on price, or checking the price difference between the best and worst colour grades for similar sized stones. Yeah, that’s right, you don’t even have to come up with questions yourself.
Some questions result in a filtered table, others result in an explanation with results in the chat window. querychat figures out, based on your question, whether you want an answer straight away, or want to inspect the filtered data yourself. Pretty cool that this only took a few lines of code.
LLMs can make mistakes
Note that it’s still an LLM that generates these queries. LLMs can make mistakes. The nice thing about
querychatthough, is that you can inspect the SQL query yourself.Most issues fall into two categories:
- Query errors: the SQL may fail to run or may not fully reflect what you intended. When it fails, the model will often try again. In this case, giving more context about the data can help.
- Result errors: even when the query is correct, the model may misunderstand or oversimplify the results, especially if that result is large or complex. The result might be that key insights are missed or misinterpreted.
Why this matters: reliability, transparency, reproducibility#
What makes the “quick launch” app so powerful is that it is far more than a chat window sitting on top of a dataset. Think back to the questions we explored earlier. We filtered, sorted, computed new columns, grouped data and used window functions. We also looked at analytical relationships without writing a single line of code. And that is only the beginning. If you want to go further, you can hunt for anomalies, create categories, build benchmarks or explore almost any analysis you can imagine. The key is that you never have to think about how to do it. You just ask.
And yes, you could ask all those questions in a typical LLM chat tool. But querychat is different. You are not relying on the model to invent answers or reason about the data internally. Instead, every single question is translated into SQL, executed on the actual dataset and returned exactly as the data dictates. And crucially, the SQL is always shown, so you can see precisely what is being run.
This brings four important benefits:
- Reliability: the LLM does not analyse or transform the raw data itself. It only generates SQL text.
querychathandles the execution of that SQL via tool calling so all results come from the real data engine, not from the model’s internal guesswork. - Transparency: every query reveals the full SQL statement. Nothing is hidden, nothing is adjusted, and you always know how the answer was produced.
- Reproducibility: since every SQL query is visible, analyses can be reused, shared, and audited.
- Safety:
querychat’s tools are designed with read-only actions in mind, meaning the LLM is essentially unable to perform destructive actions. However, to fully guarantee no destructive actions on your production database, make surequerychat’s database permissions are read-only!
Python#

R#

How it works: tool calling#
If you read The Shiny Side of LLMs
blog series, you already know a bit about tool calling. In that series we explored how LLMs can call external tools instead of trying to do everything themselves, and querychat is a very practical example of this idea in action.
Tool calling is essentially a bridge between an LLM and your Python or R session. The model does not execute code. Instead, it requests your Python or R session execute a certain function with certain inputs (e.g., a SQL statement). Once Python or R performs the execution, the result is then passed back to the model for interpretation.
So how does tool calling help us here? Well, LLMs have their strengths and weaknesses. They are not great at counting things, creating data summaries or doing basic calculations. But they are excellent at taking natural language and turning it into structured code. SQL that is. This SQL is then executed through a tool call: a function that executes the (read only) SQL. In both Python and R this means the LLM can express your question as a request to call a function with precise arguments, and the host language performs the real work. This makes it all reliable, reproducible, and safe (read only SQL).
Given that, generally speaking, LLMs are very good at writing SQL, it makes perfect sense to ask one to translate your natural language questions into SQL queries. In order to generate SQL that can be executed, the LLM does need to know something about your data: which columns are there, what do they mean, and what type are they? This schema information is shared with the model, but not the raw data. With this information, it produces an SQL query as a tool call. Now, to run SQL you need a database engine. querychat’s weapon of choice: DuckDB
. Basically, our diamonds dataset gets turned into a DuckDB database, and generated SQL queries are executed on this database. Then the results are passed back to the LLM so it can say some interesting things about it.
To summarise:
prompt → SQL query → tool call → execute SQL query → return results1
Tool calling is worth emphasising because it gives us a controlled and predictable interface between LLMs and real code execution. Instead of writing and maintaining your own custom tools, you can turn to querychat. It already provides the functions needed to turn natural language into reliable SQL that Python or R can execute with confidence.
Customising querychat: from chat to toolkit#
Alright, enough talking. You now know what querychat can do, and how it does it (high-level). You might even have brilliant ideas for your next app… In that case it would be nice to know how to build your own app with querychat. The Diamonds “quick launch” app from earlier, that you run with qc.app() (Python) or qc$app() (R), consists of a handful of methods that you can find in querychat, and we’re going to use them directly.
The main component is the QueryChat object, which has different arguments and methods.
QueryChat object#
You call QueryChat to initialise a QueryChat object (often called qc), like so:
Python#
|
|
R#
|
|
You can pass QueryChat several arguments:
-
data_sourceandtable_nameThese are the two most important arguments: they specify your data source and the name of your table that can be used for the SQL queries. The data source can be your data frame, a tibble, a table or any other Python or R data object, and the table name is usually the variable name of your data frame. In our example our
data_sourcewasdiamonds, which we also stored in a variable calleddiamonds.Python#
1qc = QueryChat(diamonds, "diamonds")R#
Generally, in R, the table name isn’t required as it can be inferred from the variable name. However, it is required when you use a database connection, which we’ll use later.
1 2 3 4qc <- QueryChat$new( diamonds, "diamonds" )You’re not limited to data objects: you can also pass a database connection to
data_source. We’ll come back to that later. -
clientWe used the
clientargument before: we use it to tellquerychatthat we want to use Claude Sonnet 4.5 (or any other model). This gets us back at the starting point of our Diamonds “quick launch” app.Python#
1qc = QueryChat(diamonds, "diamonds", client="anthropic/claude-sonnet-4-5")Alternatively, you can set the client in options the
QUERYCHAT_CLIENTenvironment variable.R#
1 2 3 4 5qc <- QueryChat$new( diamonds, "diamonds", client = "claude/claude-sonnet-4-5" )Alternatively, you can set the client in options with
options(querychat.client = "claude/claude-sonnet-4-5"). -
idThis is an optional argument, and if it’s not given it’s derived from the
table_name. When to use it? If you want to work with multiple QueryChat instances , for example. -
greetingA nice greeting message to display to your users. It’s the first thing your users see, so you better make it good! If not provided, one is generated at the start. While this one looks fine on first sight, it’s rather slow and wasteful (it costs extra tokens because it’s generated every single time). Also, because it’s generated on the fly, it’s far from consistent. Earlier, when we ran the “quick launch” app, you already might have noticed that it generated a warning message:
Python#
1Warning: No greeting provided; the LLM will be invoked at conversation start to generate one. For faster startup, lower cost, and determinism, please save a greeting and pass it to init(). You can also use `querychat.greeting()` to help generate a greeting.R#
1 2 3 4Warning message: No greeting provided; the LLM will be invoked at conversation start to generate one. • For faster startup, lower cost, and determinism, please save a greeting and pass it to QueryChat$new(). ℹ You can generate a greeting with $generate_greeting().So yes, we need a greeting! You can add your own greeting by providing a string in Markdown format.
Some inspiration on what you can put in there: basic instructions, suggestions for filtering, sorting or analysing the data, addressing data privacy concerns, or letting people know where they can get support if something goes wrong.
And if you don’t feel like writing your own greeting, or if you feel uninspired, you can let
querychathandle it! Simply usegenerate_greeting():Python#
1 2 3 4 5 6 7 8 9 10 11qc = QueryChat(diamonds, "diamonds", client="anthropic/claude-sonnet-4-5") # Generate a greeting with help from the LLM greeting_text = qc.generate_greeting() # Save it with open("diamonds_greeting.md", "w") as f: f.write(greeting_text) # Then use the saved greeting in your app qc = QueryChat(diamonds, "diamonds", client="anthropic/claude-sonnet-4-5", greeting=Path("diamonds_greeting.md"))Which give us this nice greeting:
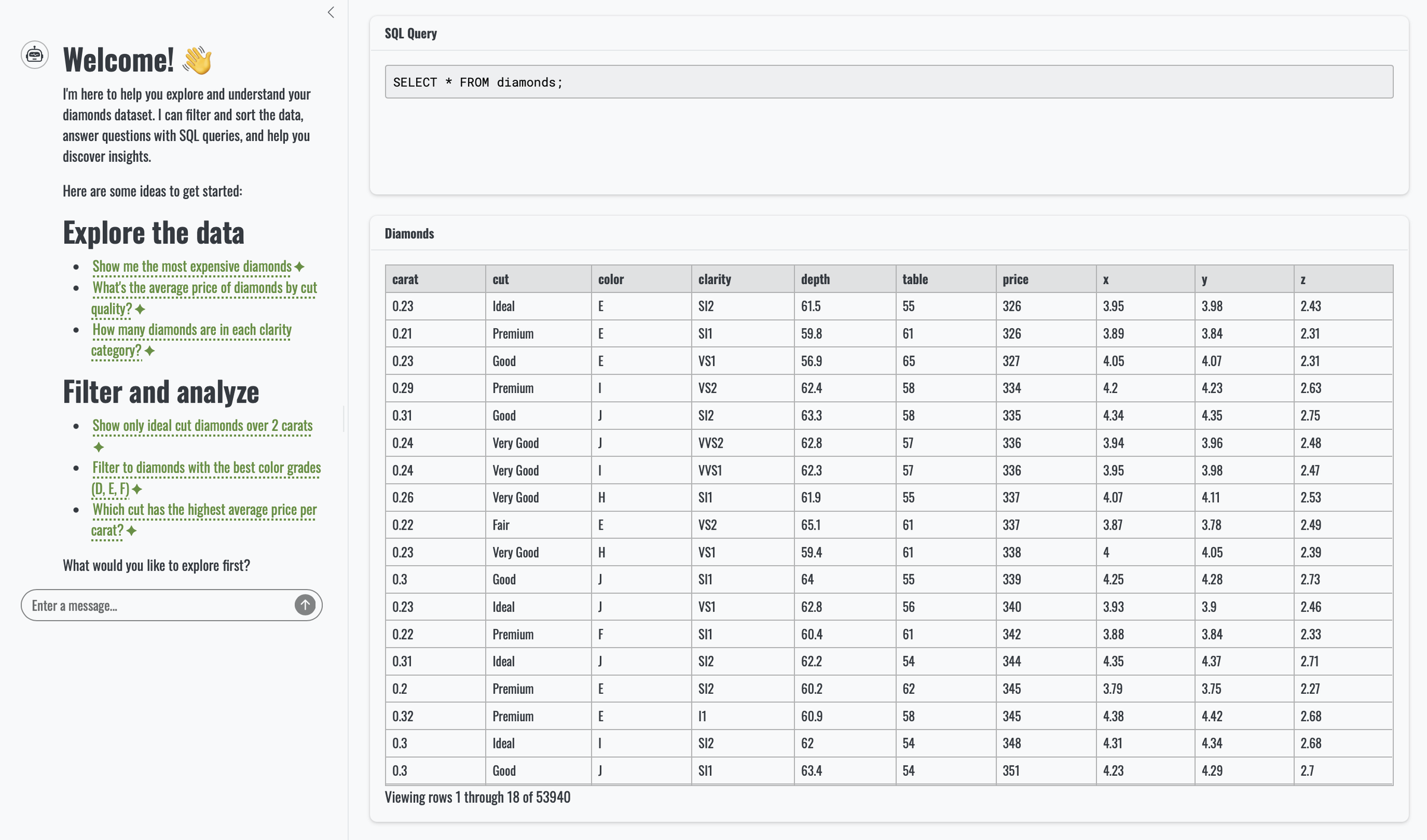
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19# Welcome! 👋 I'm here to help you explore and understand your diamonds dataset. I can filter and sort the data, answer questions with SQL queries, and help you discover insights. Here are some ideas to get started: ## Explore the data * <span class="suggestion">Show me the most expensive diamonds</span> * <span class="suggestion">What's the average price of diamonds by cut quality?</span> * <span class="suggestion">How many diamonds are in each clarity category?</span> ## Filter and analyze * <span class="suggestion">Show only ideal cut diamonds over 2 carats</span> * <span class="suggestion">Filter to diamonds with the best color grades (D, E, F)</span> * <span class="suggestion">Which cut has the highest average price per carat?</span> What would you like to explore first?R#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19qc <- QueryChat$new( diamonds, "diamonds", client = "claude/claude-sonnet-4-5" ) # Generate a greeting with help from the LLM greeting_text <- qc$generate_greeting() # Save it writeLines(greeting_text, "diamonds_greeting.md") # Then use the saved greeting in your app qc <- QueryChat$new( diamonds, "diamonds", client = "claude/claude-sonnet-4-5", greeting = "diamonds_greeting.md" )Which give us this nice greeting:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18# Welcome to the Diamond Dashboard! 💎 I'm here to help you explore and analyze this dataset of diamond characteristics and prices. I can filter and sort the data, answer questions, and help you discover interesting patterns. Here are some ideas to get started: **Explore the Data** * <span class="suggestion">What's the average price of diamonds in this dataset?</span> * <span class="suggestion">How many diamonds are there in each clarity category?</span> * <span class="suggestion">Which diamond has the highest price?</span> **Filter and Sort** * <span class="suggestion">Show me only Ideal cut diamonds</span> * <span class="suggestion">Filter to diamonds over 2 carats and sort by price</span> * <span class="suggestion">Show me the most expensive diamonds with VS1 clarity</span> What would you like to explore?You can see that the generated greeting contains a span HTML tag:
<span class="suggestion">…</span>. If you make your own greeting, you can use this tag to automatically populate the chatbox when it’s being clicked. -
data_descriptionquerychatautomatically helps the LLM by providing things like the column names and datatypes of your data (the schema information), but results can be even more accurate when you provide additional context in the data description. There’s no specific format needed, and you can add whatever information you like. To give some inspiration, this is what we could say about the diamonds dataset:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# Diamonds Dataset Description A structured dataset describing physical and quality attributes of individual diamonds, commonly used to model or predict price. ## Fields - carat (float) — Diamond weight - cut (category) — Cut quality: Fair, Good, Very Good, Premium, Ideal - color (category) — Color grade from D (best) to J (worst) - clarity (category) — Clarity grades: I1, SI2, SI1, VS2, VS1, VVS2, VVS1, IF - depth (float) — Total depth percentage - table (float) — Table width percentage - price (int) — Price in USD - x (float) — Length in mm - y (float) — Width in mm - z (float) — Depth in mmWe can save this in a Markdown file and pass it on to
querychat:Python#
1 2 3 4 5 6 7qc = QueryChat( diamonds, "diamonds", client="anthropic/claude-sonnet-4-5", greeting=Path("diamonds_greeting.md"), data_description=Path("diamonds_data_description.md") )R#
1 2 3 4 5 6 7qc <- QueryChat$new( diamonds, "diamonds", client = "claude/claude-sonnet-4-5", greeting = "diamonds_greeting.md", data_description = "diamonds_data_description.md" ) -
extra_instructionsFor further tweaking the LLMs behaviour you can use
extra_instructions. You can go nuts here: make it talk like a pirate, use an emoji in every sentence, or use an annoying amount of diamond-related phrases. You can also use this section for more practical guidance like notes on preferred spelling, tone, or handling of sensitive terms. For example:1 2 3 4 5- Assume the user doesn't know much about diamonds: keep explanations simple and accessible. - When describing diamond attributes, default to plain English. If a term is highly technical, include a short clarification. - Maintain consistent spelling in British English.Python#
1 2 3 4 5 6 7 8qc = QueryChat( diamonds, "diamonds", client="anthropic/claude-sonnet-4-5", greeting=Path("diamonds_greeting.md"), data_description=Path("diamonds_data_description.md"), extra_instructions=Path("diamonds_extra_instructions.md") )R#
1 2 3 4 5 6 7 8qc <- QueryChat$new( diamonds, "diamonds", client = "claude/claude-sonnet-4-5", greeting = "diamonds_greeting.md", data_description = "diamonds_data_description.md", extra_instructions = "diamonds_extra_instructions.md" ) -
categorical_thresholdThis threshold applies to text columns, and sets the maximum number of unique values to consider it as a categorical variable. The default is 20.
-
prompt_templateThe
prompt_templateis a more advanced parameter to provide a custom prompt template. If you don’t provide it,querychatwill use the built-in prompt, which we’ll inspect a little bit closer later.
Besides arguments, you can also call methods on the QueryChat object. One of them is cleanup(), which releases any resources (e.g. database connections) associated with the data source. You should call this when you are done using the QueryChat object to avoid resource leaks:
Python#
|
|
R#
|
|
That’s… A lot! And all you need to chat safely with your data. As you’ve seen in our earlier examples, you don’t need a lot to get started (data_source and table_name are enough, and in R you can even omit the table_name). But knowing the possibilities makes it easier to customise querychat to your liking.
Beyond chat: bespoke interfaces#
Now you know everything there is to know about the QueryChat object. You know how to add a greeting, additional context, and your favourite LLM. However, it’s time to dream bigger and time to get building! Because chatting with your data safely is one thing, but if you truly want to amaze your users you can build an entire dashboard around it. Plots, maps, tables, and value boxes that all update based on the user’s questions. Your own bespoke interface. Before we dive into that, let’s first take a step back and see if we can reconstruct the “quick launch” app.
You need two things if you want to build a Shiny app with querychat:
- The UI component (the chat window)
- A server method that deals with the results
For the UI component, there are two choices: sidebar() or ui(). The difference? ui creates a basic chat interface, while sidebar wraps the chat interface in a (bslib, for the R lovers) sidebar component designed to be used as the sidebar argument to page_sidebar.
If we want to do something with the results that get returned by querychat, we need to make use of the server() method. The server method returns:
sql: a reactive that returns the current SQL query. And, if you want to run your own queries, you can also call the$sql()method on theQueryChatobject to run queries.title: a reactive that returns the current title.df: a reactive that returns the data frame, filtered and sorted by the current SQL query.
Let’s take a look at a minimal example that rebuilds the “quick launch” app:
Python#
|
|
To keep things simple, we opted for a simple verbatim text output, but we also could’ve chosen for this combination, which is from the shinychat
package:
|
|
|
|
This actually happens in the source code for the quick launch app. It would give us the nice “copy to clipboard” feature and nice formatting. Another alternative would be the native markdown stream component in Shiny .
brand.yml
If you want to make use of brand.yml, you need to add a theme argument:
theme=ui.Theme.from_brand(**file**). Make sure you have installed the latest version of shiny with thethemeextra! You can simply add it with:uv add "shiny[theme]"(if usinguv), orpip install "shiny[theme]"
R#
|
|
Looks pretty similar to the quick launch app, right?! So that’s how it was build. Note that there a few aesthetic differences though. The quick launch app has a few extra sparks here and there, and our app makes use of custom theming with brand.yml.
So far in our diamonds adventure we have only looked at a simple table, but we can extent this idea much further and build an entire dashboard around it: value boxes, graphs, tables, maps, you name it! This is also what sidebot does, and this template is available to get you started quickly. A nice touch is the inclusion of the ✨ icon, which sends a screenshot of the visuals to the LLM for an explanation. How cool is that!
Adding querychat to your existing Shiny app#
The idea of sidebot
is certainly interesting: why build a dashboard with all kind of filters when you can just add a chat window with access to a smart LLM. You ask it questions, querychat returns some SQL and reactive filtered data, and you make sure you update the entire dashboard. Unlimited filter possibilities. And it doesn’t have to be complicated to achieve that.
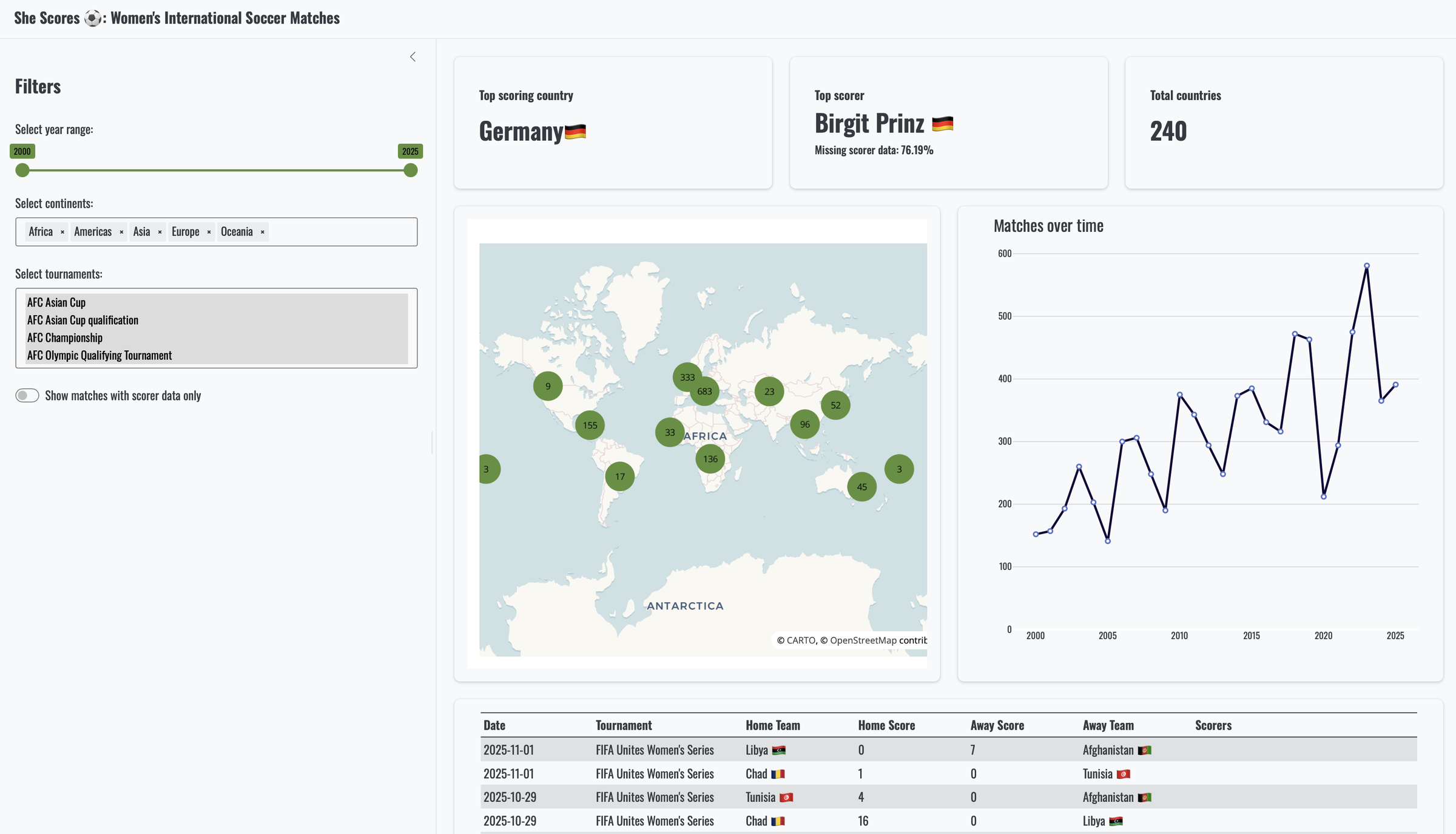
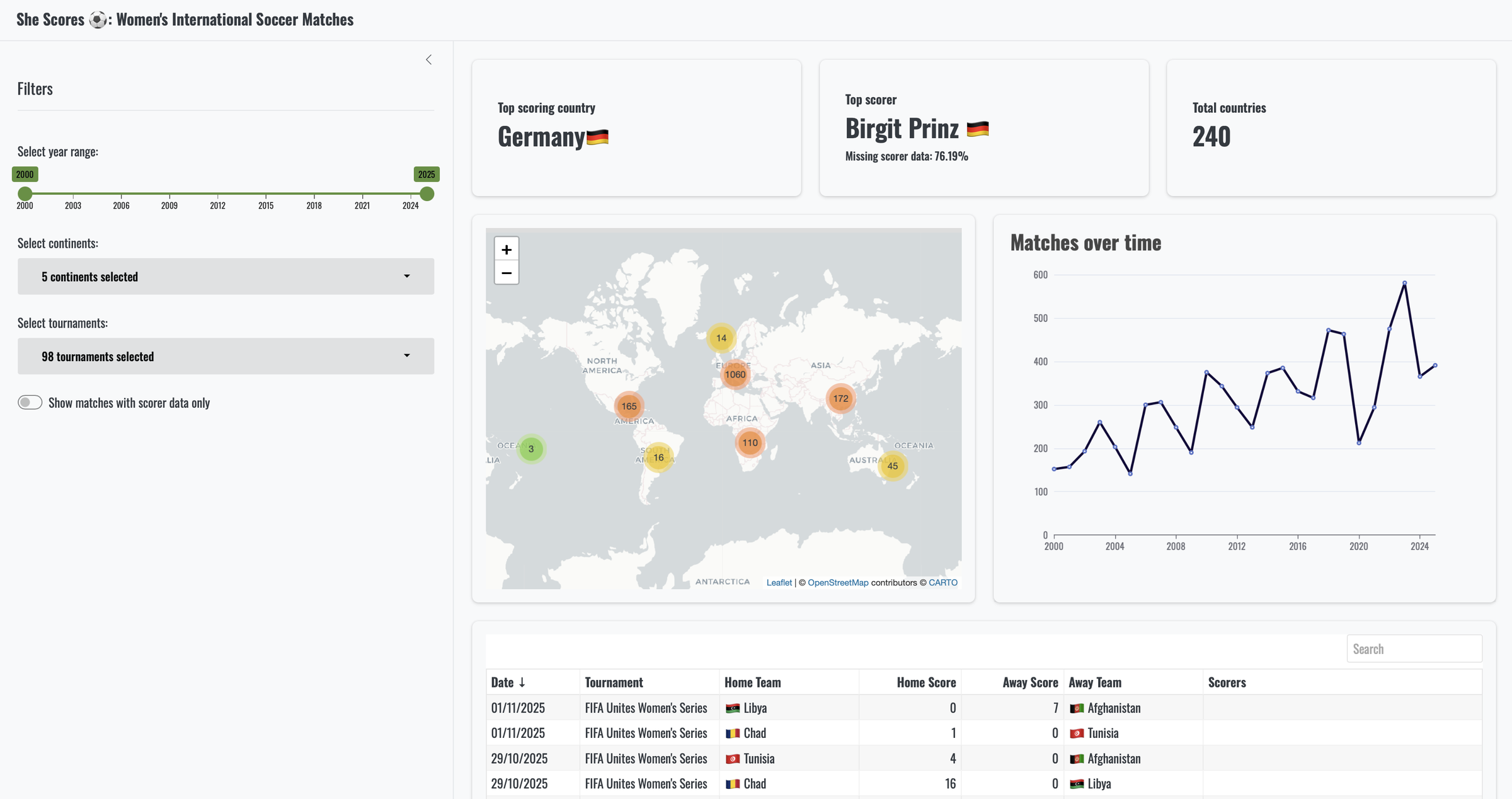
To demonstrate how easy it is, we are going to use an existing dashboard (SheScores), that currently has a number of filters in it: a slider for the year(s), a dropdown for the continent where the matches took place, the tournaments that took place on those continents, and a switch that filters the data to include only data with known scorers, or not.

So what does SheScores look like behind the scenes? We’re not going into the nitty gritty details of the SheScores dashboard, and we don’t have to if we want to add querychat to it. The most important bit of logic is stored in a reactive that contains the filtered data. It reacts to changes in any of the inputs (year, continent, tournament, scorer only or not).
The reactive, filtered_data(), forms the basis for all the elements in the dashboard: the value boxes, the map, the graph, and the table.
Python#
Tip
See GitHub for the full source code.
|
|
R#
Tip
Check out the full source code on GitHub .
|
|
Now we want to get rid of all those filters. We want a chat window instead. What do we need to change in order to use querychat? Spoiler alert: not much.
Of course we need to initialise our QueryChat object. And since we’re not talking about diamonds, we need to make sure to provide a proper soccer-themed greeting, a data description, and extra instructions:
shescores_greeting.md:
|
|
shescores_data_description.md:
|
|
shescores_extra_instrucions.md:
|
|
Now, adding querychat into the mix is as simple as replacing our inputs in the sidebar with the querychat sidebar component (sidebar()), and our reactive with the results of server().
Python#
Tip
See GitHub for the full source code
|
|
R#
Tip
Check out the full code on GitHub .
|
|
It results in a lot less code and logic too. Win-win. Thanks querychat !

Note
While we don’t have a reset button in the app,
querychatknows very well what to do when you ask it to reset the dashboard. In this case, it will display the unfiltered data, just like we started when we launched the app.
Database options#
So far we’ve only worked with simple datasets: the diamonds dataset that ships with a package, and our soccer data loaded from a .csv. But here’s how it works under the hood: even in those examples, you weren’t really querying a data frame directly. querychat hands everything off to DuckDB, which becomes the engine that executes all generated SQL. And DuckDB does so quickly and efficiently. Your data frame or .csv is effectively registered inside DuckDB, and every answer comes from real SQL running on that engine.
But what if you don’t want to work with in-memory tables at all? What if you already have a database you want to query directly? Maybe a DuckDB file, a SQLite database, Postgres, or even BigQuery? That’s exactly what the data_source argument is for. Earlier we used it with plain data frames, but it also accepts database connections. In Python, that means any SQLAlchemy-supported database
; in R, anything that DBI
can handle. querychat will inspect the schema of whatever you connect, and from that moment on the workflow is identical as before, only now you’re interacting with your own database.
Let’s take a look at how to set up querychat with another backend (SQLite) using the data_source argument.
Python#
For demonstration purposes, we’ll create a SQLite database from the SheScores data (results_with_scorers.csv).
|
|
We can then use this database in our QueryChat instance like so:
|
|
You can also create a DuckDB database from a CSV file or a pandas DataFrame, which is definitely nice for larger datasets. For more examples you can check out the package documentation on data sources .
Even if you have a database that isn’t supported by SQLAlchemy or isn’t suited for DuckDB, you can still let querychat access it. In that case, you need to implement the DataSource
interface/protocol.
R#
For demonstration purposes, we’ll create a SQLite database from the SheScores data (results_with_scorers.csv). To create a new SQLite database, you simply supply the filename to dbConnect()
. And with dbWriteTable(), you can easily copy an R dataframe into that newly generated SQLite database:
|
|
If you have a SQLite database, connecting to it works in the same manner:
|
|
Looking for more examples? Check out these database setup examples for querychat .
querychat knows how to deal with databases, and it has some convenient features for it too, especially when things go wrong: it validates whether tables actually exist and handles any issues gracefully (without cryptic error messages).
One thing to keep in mind when you move from in-memory data to real databases, especially inside Shiny apps, is proper connection management. Whenever your app opens a database connection, it also needs to close it. In Python that usually means calling engine.dispose() when the app shuts down. In R you would use dbDisconnect(conn), or rely on a connection pool. SQLAlchemy already provides pooling on the Python side, but in R you’ll want the pool package to handle this in a nice manner.
For the curious: how does querychat know what to do?#
You’ve seen what querychat can do, and you know a bit how it works conceptually. But behind all those concepts is of course some real code. So, for the curious amongst us, here’s a little peek into the querychat code!
To talk with an LLM you need a good prompt: prompt design is crucial for a good outcome. A prompt contains context and instructions that an LLM will use to come up with its answer. querychat has a set of instructions for the LLM too, the system prompt, which is stored in a Markdown file (prompt.md).
Python#
You can check out the prompt.md file here
, or you can simply print it out:
|
|
R#
You can check out the prompt.md file here
, or you can simply print it out:
|
|
So, what’s in this prompt? Let’s highlight a few bits:
|
|
|
|
The prompt is a Mustache
template. It’s a fill-in-the-blanks template: the {name} parts get replaced with real values, and the {#something} ... {{/something}} blocks only appear if that “something” actually exists. When you call QueryChat with corresponding arguments, everything gets filled in.
We talked about tool calling earlier, and there was a little note that said that there’s not just one tool. There are multiple, for different tasks. You can see that back clearly in the prompt, where we instruct the LLM to call a certain tool (e.g. querychat_update_dashboard) when it receives a request:
|
|
There are three tools in querychat:
querychat_query: used whenever the user asks a question that requires data analysis, aggregation, or calculations.querychat_update_dashboard: used whenever the user requests filtering, sorting, or data manipulation on the dashboard with questions like “Show me…” or “Which records have…”. Basically any request that involves showing a subset of the data or reordering it.querychat_reset_dashboard: if the user asks to reset the dashboard
All the tools are written as chatlas or ellmer tools. As a user, you don’t have to worry about this though. The LLM makes sure to use the rights tools, which will make sure the SQL gets executed and the data gets filtered accordingly. But hey, this section was for the curious amongst us!
Safety, control, and confidence#
At some point, everyone asks the same question: is this safe? And it’s a fair one. Luckily, querychat is designed entirely around control. The LLM never executes anything itself, never touches your data(base) and never sees raw data. Its only job is to propose read-only SQL.
Remember the moment we asked it to drop a table? It refused. Not because it’s polite, but because it’s instructed to do so. Combine that with an underlying database (the built-in DuckDB temporary database or your own) that only provides read-only access, and your data will always be left untouched.
It’s not a black box either: every generated query can be logged, inspected or audited at any time. In Shiny v1.12.0 this becomes even easier thanks to built in OpenTelemetry support via otel. If you’re curious about what that looks like in practice, you can read more in this article
.
The safety, control, and (hopefully) the confidence you’ve gained by now, make it also suitable for enterprise and regulated environments. If you need to use private or managed LLMs, you’re covered: Azure, AWS Bedrock and Google Vertex AI all provide versions of popular models that support tool calling and can work with querychat.
Other querychat apps in the wild#
It’s always nice to see what others have done with querychat. So here are few sources of inspiration:
- Do you like trail running? This Race Stats dashboard is for you!
- Is the American football league more your thing? This Shiny for Python app shows you a lot of stats.
- Joe Cheng and Garrick Aden-Buie hosted a workshop at posit::conf(2025) called “Programming with LLMs” that also contains some examples .
- And one that we mentioned before: sidebot , a dashboard analysing restaurant tipping, which is a template you can use very easily.
Whether you’re playing with a small example dataset or building something much bigger, querychat can be the companion in your app that you’re users will love. Build a whole dashboard around the chatbot, or add a touch of LLM magic for those extra side questions. With all this knowledge under your belt, you can build it all!
-
While it seems like there is only one tool call, there’s not. In
querychatthere are different tools for, surprise, different tasks. For the curious there’s a deep dive intoquerychat’s source code later in this article. ↩︎


